ECEA 5306 - ECEA 5306 Linux Kernel Programming and Introduction to Yocto
Follow-on class from ECEA 5305
Course description
Books for the class: Linux Device Drivers 3rd Edition
-
Operating System Structures: Monolithic (Linux) - Entire content of kernel is running in a protocted area
and all user applications
in user space
-
Microkernel (freeRTOS) - Some user applications running in user space, and some operating system abilities
are run from user mode
-
Hybrid Kernel (Windows, MacOSx) - Some combination of the two. Some device drivers and other are in user
mode, some are in kernel
-
Device Driver goal is to make a piece of hardware respond to well defined abstraction inerface (read(),
write() ioctl(), etc).
Should be able to be compiled seperately and added to kernel dynamically.
-
Driver should provide mechanism not policy. What capabilities are provided (mechanism), how are they used?
(policy).
Driver should allow you to set HDD system block in the manner you choose.
-
Policy free driver characteristics. Support async and sync operation. Ability to open multiple times at once,
don't add
extra layers to "simplify things" (this ends up as creating policy). The book suggests bundling the driver
with a sample program
for user space policy suggestions.
-
Kernel roles: process management (create/destroy process i/o, schedule processes), memory management, file
systems (everything is a file and types of filesystems), device control (endpoint of system operations)
kernel must have a device driver for every device in the system, networking (collect, identiy ,dispatch network packets, routing)
-
User space roles - Applications FTP server, graphics session manager, utilities that interact with drivers
-
Modules: Kernel code added at runtime. Drivers are kernel code that control hardware and may or may not be added at runtime.
-
insmod - links to the running kernel
-
rmmod - removes from the running kernel
-
modprobe - links to a running kernel, also including dependencies
-
Devices belong to a set of one classes (classes can share common access code and methods).
-
Character, block, network
-
Character device class - accessed as a string of bytes. e.g. /dev/console, /dev/ttyS0, may or may not be possible to seek
or map memory like you can do with real files. Basics of read and write are the same.
-
Block device classes - device which can host a filesystem. Transfers are always on block boundaries at the device level,
usually 512 bytes or lareger. Linux device drivers allow you to access at less than 1 block siezes, kernel manages split
blocks for you e.g. /dev/sda1
-
Network Interface class - May be a hardware device, may also be a software device like a loopback interface. Handles packets
uses a name like eth0. Use case and packet IO doesn't map well to read() and write().
-
Kernel Filesystems - maps low level blocks on a disk to directories and files. Independent of the data transfer mechanism used
to transfer blocks to/from disk. Uses devices and device drivers to perform transfers.
-
Security checks are ultimately enforced by kernel code. Kernel becomes critical point of exploit, only authorized user can load
modules
-
Drivers typically do not encode security policy. Sys admin controls based on permissions of device associtaed with driver.
Global resource changes (interaction with interrupts/firmware update may have security issues)
-
Security best practices. Don't trust user data without verifying. Don't allow anything the user sends to write any areas of mem
it should not. Zero out memory obtained in the kernel before passing outside (avoids information leakage). Length check
user space data before copying - avoids buffer overrun.
- Kernel is versioned with major.minor, no longer feature based.
-
Tainted Kernel - changed the content of the kernel while it's running and it's a non GPL module
Signal to kernel developers that they don't have the info to debug a bug report
printk is used to print messages to the kernel log. We don't have libc for kernel programming (no stdio.h)- module_init(funcname) identifies a function called when the module starts (from insmod). Similar to an event driven application
-
module_exit(funcname) identifies a function called when the module is unloaded. In kernel space if you forget to free memory, it stays allocated. No autmoatic cleanup when process exits.
Make sure to clean up anything you do in the init functions.
- Module vs Application
- MODULE_LICENSE macro clarifies that the module bears a free license. Some kernel function calls aren't available iwth propriety licenses.
- Segfault kills more than your code (most likely), may bring down the entire system
- Kernel stack is small compared to applications. Application default stack ~2MB, kernel stack may be 4k in size
- All active functions share this small 4k stack space. Don't declare large autmoatic stack allocated variables, allocate memory instead
- Floating point is generally not supported.
- Modern processors support enforcing protection against unauthorized access to resources, seperate address spaces/operating levels
- User space has a concept of lowest privldege
-
Kernel space used the highest operating level (supervisor mode). entered
with system call or interrupt.
-
Kernel runs multiple processes, multiple processes may be trying to user your driver. Interrupts run async (and kernel timers)
All kernel code should therefore be reentrant, shared data access must be handled correctly. Data structs must keep threads of execution
seperate.
-
Build process for modules is different than user space appliations. Linux source docs for kbuild are here
Make file used for the course is here
-
ls -la /lib/modules contains your currently available kernals. uname -r gives you the currently running version
The content of the build directory should have a Makefile in it that corresponds to the Makefile that was used to build the kernel currently running.
-
Recursive make means that the makefile is read twice. Useful in this instance because the first time KERNELRELEASE isn't set, used M variable
to find your makefile and read a second time with KERENELDIR set. It's done this way to allow shared use of the make tool. All the details about how to
build a module can be put just within the model.
-
.ko file is what can be loaded into the kernel via insmod after linking to kernel symbol table to load the module. Similar to the linker,
ld used when linking user space programs. Links unresolved symbols to the kernel symbol table. Modifies an in memory copy rather than the module binary
on disk.
-
When loading a module can optionally pass parameters into your module. modprope can also load modules. Modproble handles dependencies, loads
depent modules autoamtically, avoids "unresolved sybmols" message failres when modules exist but aren't yet loaded
-
rmmod can be used to remove modules
-
lsmod lists currently loaded modules and whether other modules depend on a module. Uses info from /proc/modules and /sys/modules
-
/sys and /proc - "virtual" filesystem trees used to interact with the kernel. Contents of these directories are populated by
the kernel on demand.
-
/sys and /proc could be loaded on any directory, just by convention that they are there.
-
Your driver is only allowed to load against the kernel version for which it was compiled. It does this with
vermagic. Target kernel, compiler version, processor, config variables MUST match
-
If it doesn't match, insmod will complain "Error inserting module-name:-1 Invalid module format"
-
APIs break between kernel revisions. KERNEL_VERSION macro can be used to handle compataibilties.
-
How do people keep up with these variations? Release under a GPL compatible license and let your users handle it.
Could also get it added to the mainline kernel.
-
Could also distribute in source form with scripts to compile. Dynamic Kernel Module Support (DKMS) is helpful for this
for anything that is open source, but not in the kernel.
-
Build only for a single target kernel config
-
Kernel symbol table - Your module can export symbols for use by other modules (like the dependencies in modprobe). This
is called "module stacking"
-
EXPORT_SYMBOL and EXPORT_SYMBOL_GPL can be used to make sure liceneses are compatible and only able to be used with GPL2 code
-
MODULE_LICENSE, MODULE_AUTHOR, MODULE_DESCRIPTION, MODULE_VERSION are some of these neccessary macros
-
Module init should be static, it's not meant to be used outside of the file. In this init function, register kernel facilties
(e.g. deviecs, filesystems, crypto transforms, sysfs, proc etc) and init any data structures. Data structures should be in
allocated memory! Typically uses __init so the functionss stack is discarded
-
Module exit should unregister interfaces in reversed order, and free any memory allocated in init. No auto cleanup like
userspace! Often uses __exit prefix so that the code can be discarded if it's never able to be run (like built into kernel)
-
Make sure to unregister anything you register, even if it fails! Make sure to have individual errors for each register.
Typically uses
goto which is common in kernel programming.
-
Module parameters can be definied as args. Define it with
module_param(var, type, permissions)>
Intro to Yocto
-
Yocto is a way to roll your own linux distro , not just your own root filesystem. Includes redistributable packages for
each piece of software. Launched in 2011. Includes embedded build tools and an embedded distribution Poky
-
Build system is licensed MIT. Uses text file configuration and "bitbake" tool based on Python/Bash. Builds most everything from
sourcer including all build tools. Helps make binaries reproducible.
-
source file is the same as . file in bash???
-
Yocto builds are built by the bitbake utility. Recipes are set of instructions processed by the build engine. Recipes are
.bb and .inc text files
-
.bb typically contains source and version information. .inc contains build and deploy instructions, may contain python or bash
fragments
-
Packages contain binary artifacts from the build. Images are build outputs (binary root filesystem, linux kernel image, uboot
or grub bootloader image)
-
Yocto Layer Model - Collection of directories on the filesystem virually "layered" to make an equivalent build hierarchy.
Can be used to override or add to recipes for a applying a patch or configuring something. In the course will use for aesd
-
bitbake-layers create-layer and bitbake-layers add-layer
- Yocto uses a MACHINE variable in build/conf/local.conf to set the target architecture
Singly linked lists in C
-
queue.h has a singly linked list implemenation
-
man pages here
-
Suggested assignment 1 structure
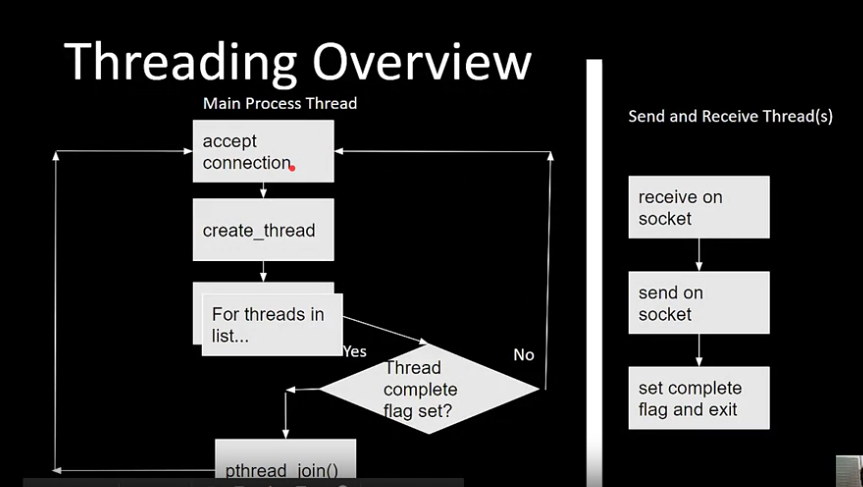
-
Try to deallocate memory in only one place, main thread is probably the best place.
-
Linked list is not thread safe! You would have to do some form of locking
Connecting to Userspace
-
scull - Simple Character Utilitiy for Loading Localities
-
Acts on memory as if it were a device
-
Portable across architectures, not hardware dependent
-
Not a "real" device driver, so no hardware interrupts. Still good for learning
-
scull0 to scull3 - four devices with memory array global and persistent. Global: data shared with all file descriptors
Persistent: Not lost if device is closed and reopened
-
scullpipe0 to scullpipe3 - FIFO Used for block and non blocking pipes
-
scullsingle - scull but only allows use for a single process
scullpriv - meant for private console only
sculluid and scullwuid - opened by one user at a time
-
/dev is one of the entries into kernel space. Device numbers/mknod map t oa kernel module.
-
mknod name type major minor
-
ls -l can show those major and minor device number. Major is type, minor is a specific device.
-
Common device drivers already have dedicated major numbers (and sometimes minor numbers)
-
Everyone else allocates for these numbers.
-
module_init and module_exit start and stop the device drivers.
Run register_chrdev(major, name, &fopstable)
-
You are responsible for unregistering chrdev! Use
unregister_chrdev
-
dev_t type holds both major and minor values associated with macros. Just a unit_32 under the hood.
Make via MKDEV(int major, int minor). Extract MAJOR(dev_t dev) MINOR(dev_t dev)
-
Example usage of scull is here
-
/proc/devices contains current list of allocated devices and associated drivers. You
will see dynamically allocated devices/drivers here.
-
Can't create device nodes (with mknod) in advance when using dynamic allocating. Parse /proc/devices after loading the
module to find major number.
Device Driver File Operations
-
file_operations, connect driver operations to device numbers.
Open, read, write, etc.
-
file is an object, and functions are methods
-
also called fops
-
file structure is NOT related to FILE* for buffered I/O
-
Represents an open file (specific open/close instance) i.e. Driver open from mknod node /dev/yourdev or
file in the filesystem
-
Called either a file or filp
-
inode is a representation of a file, not the open file descriptor
-
file_operations has a large amount of opttions
but typically only a few are definied. Read, write, and owner are usually defined. Basically this makes a "class" object of file_operations.
-
Use .owner etc to initialize anything else with null
-
Cool website with an intelligent search of the linux kernel
-

-
Char Device Registration, can use
cdev_alloc(). Gives a chunk of memory and then set it in the ops table
my_cdev->ops = &my_fops;
-
More common way to do this is to use your own structure via cdev_init, then cdev_add
-
open prototype
int (*open) (struct inode *, struct file *);. Open should check for device errors,
initialize the device on first open (if needed), update the f_ops pointer to file_operations, allocate and fill/set private
data
-
No c_dev structure in prototype! c_dev is in the union struct of the inode.
-
Can use
container_of(pointer, container_type, container_field) Macro to find where a struct is.
So something like struct scull_dev *dev = container_of(inode->i_cdev, struct scull dev, cdev);
-
release is the reverse of open. Deallocate anything in open() allocated in flip->private_data
-
If the user space programmer forgets to close the file? Kernel cleans up automatically at process exit. Your driver
is guaranteed exactly one release() per open()
-
Make Driver Code -> Load via insmod or modprobe -> addresses for functions are now locatable (e.g. open/register_chrddev) -> update procfs/devices to include new
device -> register in fops table -> read /proc/devices via module_load_script -> use mknod to make the driver -> new entry in root filesystem
-> userspace application can open /dev/mydriver -> links to driver source code in kernel
-
kmalloc(size_t size, int flags) is similar to malloc. Malloc/free are not available becuase glibc doesn't exist.
Just using GFP_KERNEL as our flag for now.
-
Allocate memory! Stack space is very small within the kernel.
-
fops has
ssize_t read(struct file *filep, char __user *buff, size_t count, loff_t *offp. Same prototype for
write. buff is a user space pointer, cannot be directly accessed by kernel code. Not guaranteed to be usable within the kernel.
-
Can use
unsigned long copy_to_user(void __user *to, const *from, unsigned long count) and
unsigned long copy_from_user(void *to, const void __user *from, unsigned long count); to move between
user and kernel space. Similar to memcpy, but deals with any architecture specific issues.
Assignment 7
-
buildroot rootfs-overlay is a way to add content to root file system/override content from other packages
after being built. Content will be placed in the rootsfs at the spceified path (use a relative path!)
-
Will be compliing kernel modules for out of tree kernel modules. Build root section on this
-
Good SO Example as well
-
Also will be making a circular buffer in the userspace, this will move into the kernel space on the next assignment.
-
Kernel Debugging is harder. Can use gdb and /proc/kcore, but can't use halt, set, breakpoints, modify memory
-
Not easily traced
-
Often difficult to reproduce bugs, especially timing related. Often bugs crash the system and destroy evidence. No cleanup methods
are guaranteed
-
To debug - enable "kernel hacking" in your kernel menuconfig
-
CONFIG_DEBUG_KERNEL, see Linux Device Drivers Chapter 4 for full options
-
printk() is the most common thing people use
-
EMERG, ALERT, CRIT, ERR, WARNING, NOTICE, INFO, DEBUG are supported
-
printk(KERN_DEBUG "I'm printing pointer %p\n", ptr);
-
dmesg prints kernal output
-
/proc/sys/kernel/printk can be used to control prints redirected to the console
-
printk is safe to use anywhere (interrupt safe). Writes output to a circular buffer. A different
task writes this buffer elsewhere.
-
Debug prints should not be in production! A macro like PDEBUG can be useful to turn these
on and off. Redine PDEBUG as printk or to nothing if debug mode is off
-
Use strace to trace system calls and interactions between user space program and the driver.
-
Can use dynamic debug to turn on and off specific prints from the CLI. Don't need to recompile the driver,
don't need special debug builds.
-
printk_ratelimited can be used to prevent log from being flooded
-
System faults - due to a bug in a specific driver, may result in a "panic" stopping the kernel.May
need to reboot the system
-
oops message e.g. null pointer dereference of use pointer incorrect value
Describes where in code the fault occured
-
objdump shows you assembly content associated with an object file (in this case a .ko)
Will intermix source if you have debug info for kernel module build. If cross-compiling,
use the corresponding objdump!
Kernel Drivers and Concurrency
-
Concurrency bugs "easiest to create and some of the hardest to find"
-
Made ubiquitous by Symmetric Multiprocessing (SMP Systems), Basically
sharing ram between CPU's. AMP (Asymmetric Multiprocessing) has a part
of RAM dedicated to each CPU. Ths is harder to write an OS with.
-
Task switching can make rudimentary gate checking not present! Need to properly lock
anything that is accessing dangerous memory/pointers
-
This may seem unlikely, but a "one in a million event happens ever few seconds" with modern processors.
Probablities can also be more prominent on certain hardware platforms.
-
Dan's law = It will happen when you show your boss
-
Kernel code is preemptible, driver code can lose the processor at any time!
-
Device interrupts are completely async
-
The device could dissappear!
-
Avoid race conditions by avoiding shared resources (i.e. global variables)
-
race conditions can still happen because allocating memory and passing the
pointer to the kernel can still make a sharing situation
-
Is hardware or another resource shared beyond a single thread of execution?
Is it possible the thread could encounter an inconsitent view of the resource?
If either are yes, you must manage resources!
-
Can use locking or mutual exclusion.
-
When yo notify the kernel about an object, it must continue to exist and function
until no outside referneces exist. References to objects should be tracked, don't
make object availble to kerne luntil it is ready.
Critical Sections/Atomic
-
Atomic operations happen at once, something like a = b (may depend on variable size/arch), not a++
Like in a single instructions, it can't be preempted!
-
Critical section includes code that can be executed by only 1 thread at a time.
Can use Semaphores & mutexes, work with/use sleep. Can also use spinlocks (work in all cases, including
when you can't sleep)
-
It may not be safe to sleep in a critical section, it may be called from an
interrupt handler, latency requirmements, could also be holding other critical resources.
-
Will this critical function sleep, or call a function that sleeps?
-
kmalloc can sleep! It's in the docs.
Checkout the default flag for Kmalloc GFP_KERNEL.
-
Semaphore are integer value + functions P() and V()
-
P() when value > 0: value is decremented, process continues
-
P() when value <= 0: process blocks until value > 0
-
V() increments value
-
Initializes value to 1. P() = lock() and V() = unlock()
-
this is an older way to do it, the kernel now has dedicated mutex
operations. Mutex is a special case of the Semaphore
-
Can use DEFINE_MUTEX(name_of_mutex), typically means it is global
-
Can also include it in a structure with
mutex_init()
Make sure the mutex_lock is initalized first!
-
P() maps to the down() operation in the LDD3 book. down() and
down_interruptible() are the same, but the user can intterupt
with SIGTERM/SIGKILL. 0 return means the semaphore was obtained
This is typically what you want to use.
-
down_trylock(struct semaphore *sem) never sleeps,
- if obtained, 1 if someone else is holding. Thread which has
completed "down" successfully "holds" has "taken out" or has "acquired"
the semaphore.
-
void up(struct semaphore *sem) on return of up() your
thread no longer hold sthe semaphore
-
1 call to down should result in exactly 1 call to up, Semaphores
must all be released in error paths! Goto is ok in Kernel programming,
but not strictly neccessary.
-
Mutex was added to the Linux Kernel. It is the same thing as a
semaphore, just simpler to understand/
-
mutex_lock -> down
-
mutex_trylock -> down_trylock
-
mutex_lock_interruptible -> down_interruptible
-
mutex_unlock -> up
-
nested -> used for multiple locks, ordering between
-
Mutex is used in scull! It must be initalized before cdev_add(),
since "no objet must be made available to the kernel before it can function properly"
-
Use -ERESTARTSYS when retrying the operation is the right thing to do (undo any user visible changes)
-
Use -EINTR when you can't undo previous changes
-
Balance each lock with unlock (including error cases)
-
Only writer threads need exclusive acess. An infinite number of
reader threads can access as long as the writer threads are blocked.
This can be used for Reader/Writer Semaphores.
-
Similar functions, but (down_write, up_write etc.), but down_write_trylock/down_read_trylock return 1
instead of 0 on success.
-
downgrade_write converts a write lock to a read lock
-
Writers get priority. Use when write access is rarely required and held
only briefly.
-
Completions are similar to sempahores (and you could use semaphores), and used
to wait for an activity to complete. Designed for the not availble case.
-
complete/complete_all support use in interrupt handlers.
-
if you are thinking about using yield, or msleep, use wait for completion and complete
instead! Checkout the API here!
-
There are timeout and interruptible and interruptible_timeout versino of wait_for_completion!
-
Also are complete_all to wait for all current and future completes.
Spinlocks
-
Spinlocks can be used in code which cannot sleep i.e. interrupt handlers
-
Higher performance than semaphores when properly used
-
Concept: single bit in integer value + tight loop spin. atomic test and set of bit, wating processors is executing a tight loop
-
Need to be careful not to use it for too long, otherwise it's just checking the value over and over!
-
irqsave/irqrestore are different version of spin_lock/spink_unlock. They disable interrupts,
have some flags to store whether interrupts werepreviousy enalbed/need to be re-enabled. irqrestore re-enables
interrupts.
-
regular spin_lock/spin_unlock does not disable/renable interrupts. Could cause a deadlock if an interrupt occurs!
-
Any code must be atomic while holding the spinlock, can't sleep, can't reqlinquish the processor for anything other than interrupts
-
Difficult to know what functions sleep. Most functions which might allocate memoery might also sleep
-
Second rule, hold the spinklock for as little time as possible
-
Locking rules should not be ambigious. Define a lock to control
access to specific data. Design from the beginning! Write functions
which assume caller has allocated the lock and document assumptions
explicitly.
-
If there are multiple locks, make sure you always acquire in the same order
every time. Otherwise you could cause a deadlock where multiple threads
are waiting for each other to release a specific lock. They should also
be released in the opposite order.
-
Lock ordering rules are poorly documented (read the source :( )
-
Avoid using multiple locks whenever possible.
-
Obtain your driver locks before locks used in other parts of the kernel. Minimzes the
chance you block when holding the most popular lock
-
Hold semaphores before spinlocks, semaphores may sleep, but you can't sleep with a spinlock
-
Alternatives to locking - Use atomic variables and bit operations. Guaranteed atomic types on all
architectures. Bit operations also!
-
Use a lock free algorithm (circular buffer with exactly 2 threads and atomic count values). read Copy Update, old copies
remain valid, cleanup happens when references are released.
more debugging
-
Nice to use userspace/kernel space debug print macro here
-
linux trace toolkit, traces events in the kernel
-
SystemTap
-
debugfs can make information available to userspace. /proc, intended
for process information, but has fallen out of favor
-
/sysfs - highly organized/restricted content
-
Can use kmemleak to detect memory leaks in the kernel
-
strace is super useful to look at the kernel calls. Can call it like:
strace -o /tmp/strace.txt ./drivertest.sh drivertest.sh could
be whatever script. Use -f to trace any child processes via fork
ioctl
-
ioctl is a system call on a file descriptor which passed to the driver, similar to read/write, but more unstructured.
Identifies a command to be performed and another argument (typically a pointer)
-
The ioctl call allows you to interact with your driver from userspace, passing a command and optional associated argument pointer
-
Cannot access ioctl from user space! Need another program to issue the ioctl script. Common interface used for device control,
request for a device other than read/write for example: Lock a door, eject media, report information
-
Userspace prototype
#include
int ioctl(int fd, unsigned long request, ...);
-
... traditioanlly represents varargs, typically a single optional argument argp char *argp. It's this
because void * wasn't valid C when this was written!
-
Easiest and most straightfoward choice for device operations. It has fallen out of favor with kernel developers becuase of the
unstructured system calls, difficult to audit, not well documented. Alternatives include embedding commands into the data stream
and virtual filesystems like sysfs.
-
Latest kernel is using slightly different function prototype from ldd3. There is a 64 bit vs 32 bit divide in ioctl, because the
optional arg is passed in the form of an unsigned long regardless of whether it was given by the user as an integer or pointer. This
long may not correspond to pointer size on a 64 bit system, or when compiling for 32 bit. Use compat_ioctl to auto-handle differences
in arg size between 64 bit and 32 bit.
-
ioctl example here, it's using CASE statements with MACROS.
-
Using MACROS to help generate unique cmd comdes for each device driver using magic numbers. Avoids issuing correct command to the wrong driver.
Typically uses a character as a "magic number". SCULL is using 'k'. This is super gross. A list of current ones in linux are here.
-
IO Macros work like (magic number, sequence command number, type of data transfer) so like this in SCULL.
-
_IOC_READ (_IOR) - transfers from kerenl to user space
-
_IOC_WRITE (_IOW) - transfers from user to kernel space
-
Some ioctls are recognized by the kernel, decoded before passing to your driver. Avoid magic type "T" to avoid these!
-
write() can be used as an ioctl alternative. Write control sequences the deivces. especially useful for devices that don't
transfer data. Basically
echo "start" > /dev/yourdevice May or may not end up being more complicated.
Sleeping in the kernel
-
Process can sleep when blocking for a process. This means the the process is removed from the run queue.
-
Never sleep when holding a spinlock, seqlock or RCU lock. Attempts to obtain spinlocks consume processor resources while waiting for that event
to happen. It's a recipe for deadlock.
-
Never sleep if you've disabled interrupts. Interrupt latency would suffer.
-
Avoid sleep/keep durations short while holding a semaphore/mutex consider whether you could introduce a deadock. It's ok to use a semaphore because other
threads waiting for the semaphore aren't spinning, they are sleeping. Need to be careful overall, it is easy to introduce a deadlock. It's safe to sleep
if any code attempting to obtain the semaphore won't prevent your wake-up condition. You can't really avoid this with other functions.
-
Make sure you reevalute all states after you come out of the sleep as well. Lock could have changed after waking.
-
Simple Sleeping
wait_event(queue, condition) Also have timeout and interruptible versions. Waitqueue is the queue.
wait_queue_head_t my_queue; init_waitqueue_head(&my_queue) The condition is using some macro magic to change the boolean value
where it is reevaluated constantly. Could look something like wait_event_interruptible(wq, flag != 0); That condition flag != 0,
is constantly reevaluated. Weird looking C Code!
-
There are also
wake_up(wait_queue_head_t *queue) (and an interruptible version). Make sure this is in a different process or interrupt to
call wake_up. wake_up calls all processes on the wait queue. wake_up_interruptible wakes up only interruptible processes.
-
Could use wake_up to wake_up reader queue when new data is availble due to write. Could then wake up writer_queue because new space is available.
-
Example in scull's pipe.c with waiting/wake_up . This is blocking i/o!
-
Output and input buffers are often useful for handling blocking i/o on real devices. This means any blocking is on access to the buffer rather than
access to the device. Benefit when memory access is faster than device access.
-
How a process sleeps: TASK_RUNNING - able to run, may not be executing. TASK_INTERRUPTIBLE and TASK_UNINTERRUPTIBLE two types of sleep
-
schedule() actually calls the scheduler. You can see this within the wait_event macro! This is what actually puts the function to sleep.
The schedule() function will return periodically, and allow your driver code (via macro wait_event_interruptible or similar) to check for a condition.
-
What if a process requests O_NONBLOCK on open()? This is included in the filp->f_flags (within file pointer.) It will return EAGAIN, it won't
wait! Non block test script is available here. C
source code is here.
Poll and select
-
poll and select determine whether a device/file can be read without blocking or wait for a file descriptor to become ready.
Support implemented by poll method in device driver. Implements the poll driver in user space. Within file pointer!
__poll_t (*poll) (struct file *), struct poll_table_struct *);
-
Call poll_wait on any wait queues which could indicate poll status changes. Kernel will wait on these as neccessary. Returns bit mask
of currently available operations. Same ideas as wait queues. Example in pipe.c is here
-
Read Rules: when data is avaialble in input buffer, read should return immediately with at least 1 byte. Poll should return POLLIN|POLLRDNORM
If no data in input buffer read should block until one byte is there OR if O_NONBLOCK return with value -EAGAIN. poll should report unreadable (read flags all 0).
At end of file, read should return immediately with value of 0, poll should report POLLHUP.
-
Write Rules: when space is available in the output buffer, write should return without delay, accepting at least one byte. poll should report
POLLOUT | POLLWRNORM. When the output buffer is full, write should block until space is freed or if O_NONBLOCK is set return -EAGAIN. poll should report file
is not writeable (write flags are 0). Never make a write call wait for data transmission (transfer from output buffer to device) even if O_NONBLOCK is not set.
driver must provide fsync.
-
Seeking on a device: default lseek just sets filp->f_pos. llseek file operation can be implemented if the seek needs a custom operation for the device.
Call nonseekable_open in your open function if seek doesn't make sense for your device. Somethinkg with data flow like a serial port/keyboard.
-
Access Control from open(). Single-Open - only one process can open at a time. scullsingle example, obtain atomic in open, release in release()
Single User, compare process uid in open(), return -EBUSY when in use. Alternative to returning -EBUSY - block in open()